python爬取区块链浏览器上的交易列表数据
前言
2022年6月3日 端午节安康。
今天主要分享如何利用爬虫爬取区块链浏览器上的交易列表数据。
原因
dune上没有bsc链上的转账明细数据表。Footprint Analytics上现有的bsc_transactions表transfer_type粒度不够。
环境
python 3.7
数据存储:mysql 5.7
缓存:redis 6.2.6
开发工具:pycharm
思路
(1)所有协议、合约、swap地址转账信息全爬不太实际,对存储要求比较高。所以针对需要分析的协议,专门去爬取对应智能合约转账是个不错的选择。
(2)区块链浏览器肯定是有反爬机制的。所以在代理选择上,要选择国外的代理。国内的代理都访问不到,具体原因你懂的。本文中不涉及代理部分,因为国外的代理厂家之前没有了解过。不过即使是上代理,对代码层面改动也比较小
(3)采用了urllib同步请求 + 范围内随机时长程序休眠。减少了被风控的概率。但是也降低了爬虫的效率。
后面再研究用scrapy或异步请求 [1]
[1] 同步:请求发送后,需要接受到返回的消息后,才进行下一次发送。异步:不需要等接收到返回的消息。
实现
找到需要爬取合约的具体地址:
第一页
http://bscscan.com/txs?a=0xbd3bd95529e0784ad973fd14928eedf3678cfad8第二页
https://bscscan.com/txs?a=0xbd3bd95529e0784ad973fd14928eedf3678cfad8&p=2第三页
https://bscscan.com/txs?a=0xbd3bd95529e0784ad973fd14928eedf3678cfad8&p=3....
可以知道 p = ?就代表页数。
然后F12 点击“网络”,刷新界面,查看网络请求信息。
主要查看,网页上显示的数据,是哪个文件响应的。以什么方式响应的,请求方法是什么
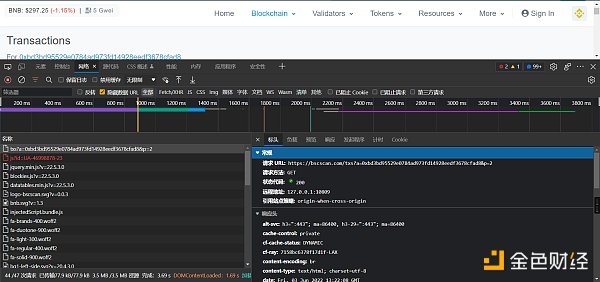
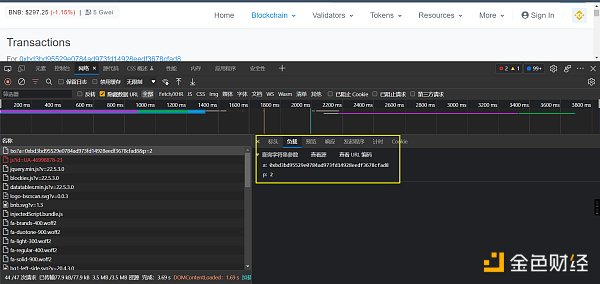
如何验证呢,就是找一个txn_hash在响应的数据里面按ctrl + f去搜索,搜索到了说明肯定是这个文件返回的。
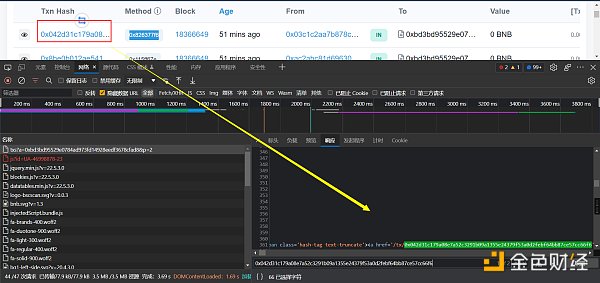
查看响应的数据,是html的格式。在python里面,处理html数据,个人常用的是xpath(当然,如果更擅长BeautifulSoup也可以)
在python里面安装相关的依赖
pip install lxml ‐i https://pypi.douban.com/simple同时在浏览器上安装xpath插件,它能更好的帮助我们获到网页中元素的位置
XPath Helper - Chrome 网上应用店 (google.com)
然后就可以通过插件去定位了,返回的结果是list
**注:**浏览器看到的网页都是浏览器帮我们渲染好的。存在在浏览器中能定位到数据,但是代码中取不到值的情况,这时候可以通过鼠标右键-查看网页源码,然后搜索实现
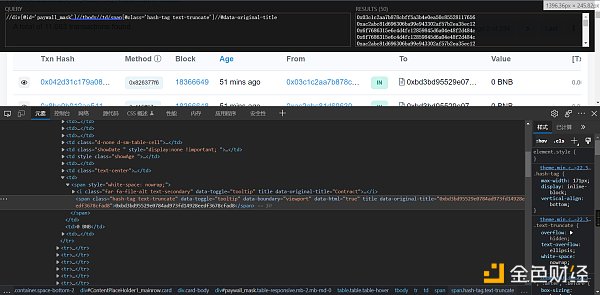
然后就是利用redis,对txn_hash去重,去重的原因是防止一条数据被爬到了多次
def add_txn_hash_to_redis(txn_hash): red = redis.Redis(host='根据你自己的配置', port=6379, db=0) res = red.sadd('txn_hash:txn_set', get_md5(txn_hash)) # 如果返回0,这说明插入不成功,表示有重复 if res == 0: return False else: return True # 将mmsi进行哈希,用哈希去重更快 def get_md5(txn_hash): md5 = hashlib.md5() md5.update(txn_hash.encode('utf-8')) return md5.hexdigest()最后一个需要考虑的问题:交易是在增量了,也就是说,当前第二页的数据,很可能过会就到第三页去了。对此我的策略是不管页数的变动。一直往下爬。全量爬完了,再从第一页爬新增加的交易。直到遇到第一次全量爬取的txn_hash
最后就是存入到数据库了。这个没啥好说的。
以上就可以拿到转账列表中的txn_hash,后面还要写一个爬虫深入列表里面,通过txn_hash去爬取详情页面的信息。这个就下个文章再说,代码还没写完。
今天就写到这里。拜拜ヾ(•ω•`)o
来源:Bress
作者:撒酒狂歌
三箭资本共欠27家加密公司35亿美元(附名单)随着三箭资本(3AC)清算的进行,其背后的贷款细节逐渐得到披露。三箭资本破产清算监督人Teneo2022年7月18日在网上上传了一份长达1157页的维京群岛法院法庭文件,披露了三箭资本(3AC)贷款细节。三箭资本(3AC)一共...
P2E 已死 用第一性原理重新思考链游链上游戏设计要基于链上环境,基于第一性原理的游戏设计思路。撰文:空岛,ParallelVentures投资经理随着熊市的深入,市场越发的无聊了,之前的主流叙事都尽显疲态,Defi的发展陷入了瓶颈,NFT的交易量也节节下滑,...
Layer2全览:数据、扩容方案、生态对比Layer2已经成为以太坊最重要的叙事。随着Optimism推出代币,Arbitrum进入奥德赛,用户参与Layer2的热情被最大程度地激发出来。Layer2的终极方案——ZK-Rollup的代表zkSync、Starkware近期也受到关注。L2beat.com显示...
一文读懂MakerDAO:以太坊“最疯狂”的DAPP为什么说MakerDAO是以太坊上“最疯狂”的DAPP?在一场对VitalikButerin的采访中,主持人对VitalikButerin提问:“What’sthecraziestapplicationoftheEthereumthatyou’vecomeacrosslately?”(你最近遇到的“最疯狂...
疯狂数字藏品:15元成本卖15000元,姚明、周杰伦“入坑”数字藏品火了。2021年初,数字艺术家Beeple将自己之前创作的数千幅画作组成了一幅数字艺术作品《每一天:最初的5000天》,最终该作品以6934万美元的价格拍出,这是拍卖机构佳士得首件以NFT形式拍卖的艺术品。随后,...
不止中本聪,区块链“鼻祖”其实是位深藏功与名的神秘华人近几年来,越来越多的互联网人开始往Web3迁徙,试图在这片新大陆上开荒拓土,寻找下一个时代机会。而这一切的起源,都要追溯到14年前“区块链”技术的诞生。区块链的去中心化、分布式网络构想是如今各种Web3应用诞生...
金色前哨|Liquity推出DeFi机制Chicken Bonds金色财经报道,7月13日消息,去中心化借贷协议LiquityProtocol宣布推出一个DeFi机制ChickenBonds,项目和DAO能够通过该协议建立流动性(POL)。ChickenBonds探索了一种新颖的本金保护绑定机制,可提高最终用户的收益机...
三箭资本败局连锁反应下:多方机构齐声撇清关系曾位列一线VC的三箭资本,在牛市丰沛流动性的无序扩张后,逐渐迎来了属于自己的终局。三箭资本的溃败</h2>三箭资本是以加密货币为重点的风险投资公司之一,一度被视为加密新贵,他们的最佳投资包括:Avax、Near、Der...
演化中的web3游戏web3游戏不可避免的到来目前游戏作为数字时代人们娱乐的最主要方式之一,正在创造极大的产值,在2021年,其中光是超过1亿美元年收入的手机游戏就达到174个。(超过1亿美元年收入的手机游戏趋势图,Messari数据)随着...
Messari:Ocean协议当前面临的挑战及其应对计划本文要点Ocean Protocol是一组去中心化数据共享技术,旨在降低访问高质量数据的障碍。Ocean生态系统包括数据市场和数据编排智能合约的集合。Ocean V3和V4采用自动化做市商(AMM)和数据池,其数据池促进数据买卖双方...